Januar Flyer
Monats-Flyer Project BID 2.0: Januar
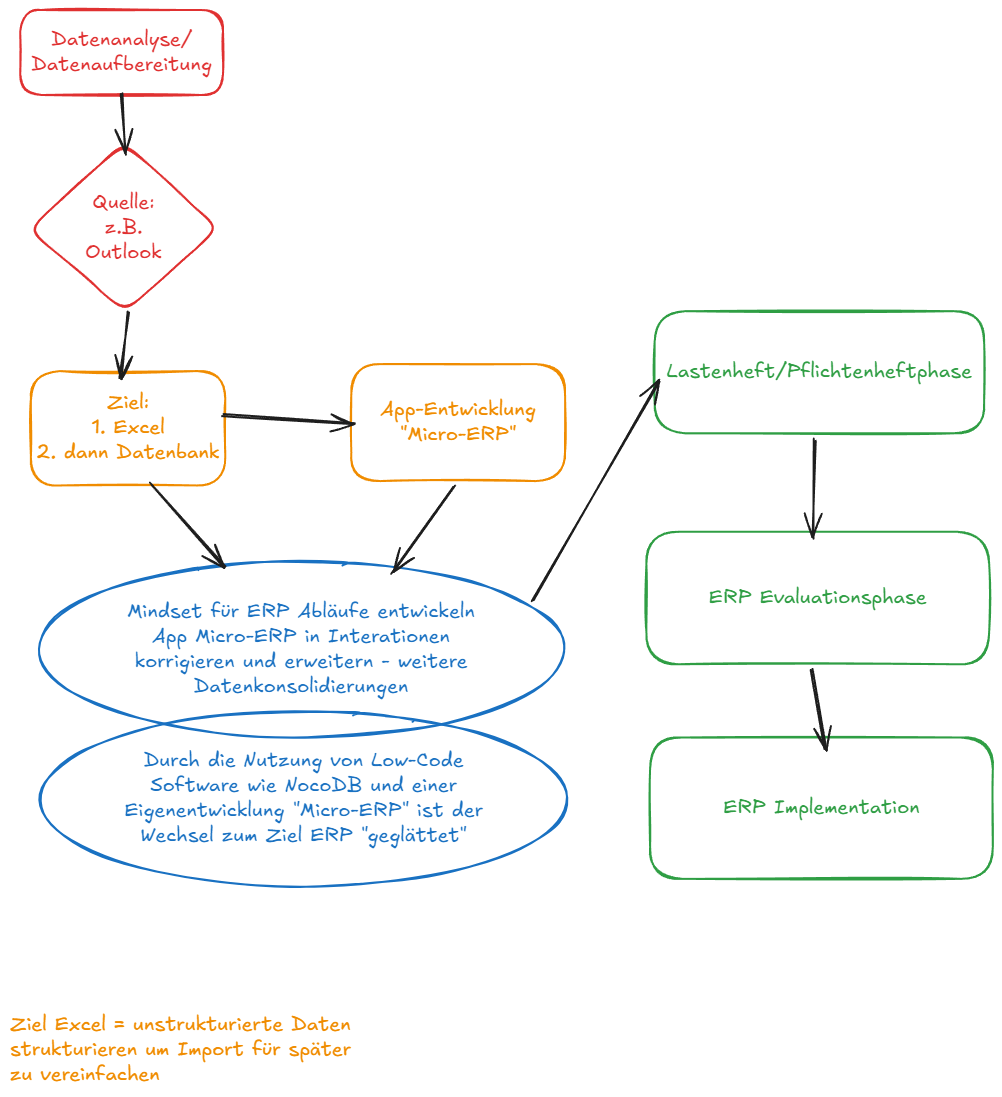
Nach verschiedenen Gesprächen und Analysen haben wir eine klare Leitlinie definiert, an der wir aktuell arbeiten:
Unser Ziel ist zunächst die strukturierte Datenaufbereitung. Aus vorhandenen, unstrukturierten Daten – etwa aus Outlook oder handschriftlichen Notizen in Kundenakten – bauen wir eine zeilenbasierte Struktur (ähnlich einer Excel-Tabelle) auf.
Diese führen wir in verschiedenen Schritten Zielsystemen wie Excel, NocoDB und OLTP-Datenbanken (z. B. PostgreSQL) zu. Dabei ist NocoDB weit mehr als ein Zwischenschritt: Es dient uns als Plattform, um unmittelbar von den aufbereiteten Daten zu profitieren und diese beispielsweise für Analysen (Business Intelligence) zu nutzen. Die PostgreSQL-Datenbanken bilden wiederum das stabile technologische Fundament für unsere Eigenentwicklung, das ‚Mikro-ERP‘.
Damit erreichen wir, dass die Daten nicht nur aufbereitet sind, sondern wir bereits in der Philosophie eines ERP-Systems denken und handeln. Durch die (Interims-)Nutzung dieses ‚Mikro-ERPs‘ können wir die Daten im laufenden Betrieb weiter verfeinern und wertvolle Praxiserfahrung sammeln.
Hier ist ein schlichtes Schaubild, das diesen Prozess visualisiert:
Was haben wir bei der Datenanalyse und -aufbereitung bereits erreicht? Ein Großteil der Kundeninformationen ist in den Outlook-Kontakten gepflegt. Während die linearen Daten im linken Teil einfach zu extrahieren waren, mussten die Informationen im rechten Teil – also die Daten im Notizblock des Kontaktfensters – erst durch eine Programmierung aufbereitet werden.
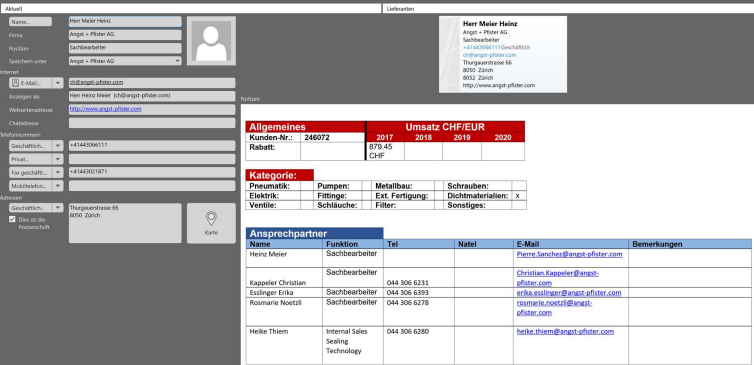
Das habe ich nun umgesetzt: Ich habe ein PowerShell-Skript geschrieben, das diese Notizdaten in ein HTML-Format exportiert. HTML lässt sich anschließend sehr eƯizient mit Python und Frameworks wie „BeautifulSoup“ strukturieren. So entsteht eine klare 1:n-Beziehung (eine Firma hat viele Kontakte). Diese Daten sind nun in zwei Excel-Tabellen gespeichert und werden regelmäßig aktualisiert, sobald wir den neuesten Stand benötigen.
Firmen:

Kontakte:

Über einen Schlüssel hier z.B. „22“ können diese beiden Tabellen später miteinander verknüpft werden.
Sämtliche Programmlogiken speichere ich in meinem GitHub-Repository, sodass die Quellen für alle Entwicklungen jederzeit verfügbar sind. Eventuell sollten wir noch ein GitHub Account für Nanovis anlegen, damit immer alle Coding-Projekte auch in Euren Besitz geklont werden können. Simples Abspeichern von Quellen auf der Festplatte halte ich für ungünstig.
Applikationsentwicklung Micro-ERP Die Autoren des aktuellen Excel-Konstrukts für die Auftragsabwicklung haben hervorragende Vorarbeit geleistet. Sie haben einen logisch zusammenhängenden Ablauf geschaƯen, in dem sich die Mitarbeiter der Auftragsabwicklung (Iris und Harishma) von der Anlage präliminärer Kundenstammdaten über verschiedene Registerkarten wie Auftragsdossier, Lieferschein und Rechnung bis hin zur Übergabe an die Fertigung bewegen.

Bisher ist ein Vorgang jedoch ein „Dateibündel“ – das ist für die Skalierung nicht ideal. In ERP- oder Warenwirtschaftssystemen sind alle Stamm- und Bewegungsdaten tabellarisch angeordnet und miteinander verknüpft. Die Applikationslogik sorgt dafür, dass diese Daten zum richtigen Zeitpunkt an der richtigen Stelle dargestellt werden.
In der Programmierung bilde ich die Logik aus dem vorhandenen Excel-Konstrukt nach, baue jedoch den Bezug zu einem relationalen Datenbankmodell auf. Stammdaten- und Bewegungsdaten-Container werden tabellarisch aufgearbeitet, sodass sie systematisch gespeichert und extrahiert werden können.
Der Entwicklungsprozess orientiert sich direkt an den gewohnten Registerkarten aus Excel:
1. Firmenstammdaten
2. Anlage von Aufträgen
3. Übergabe an die Fertigung
4. Druck der Auftragsbestätigung
5. Abwicklung von Lieferschein und Rechnung (Anlage & Druck)
Sobald der Stammdatencontainer für die Firmeninformationen steht, können darauf basierend neue Geschäftsobjekte angelegt werden. Jeder neue Kundenauftrag bedient sich dann automatisch der zentral gepflegten Stammdaten.
Hier ein Bild dazu, wie dieses Konzept grafisch aussieht:
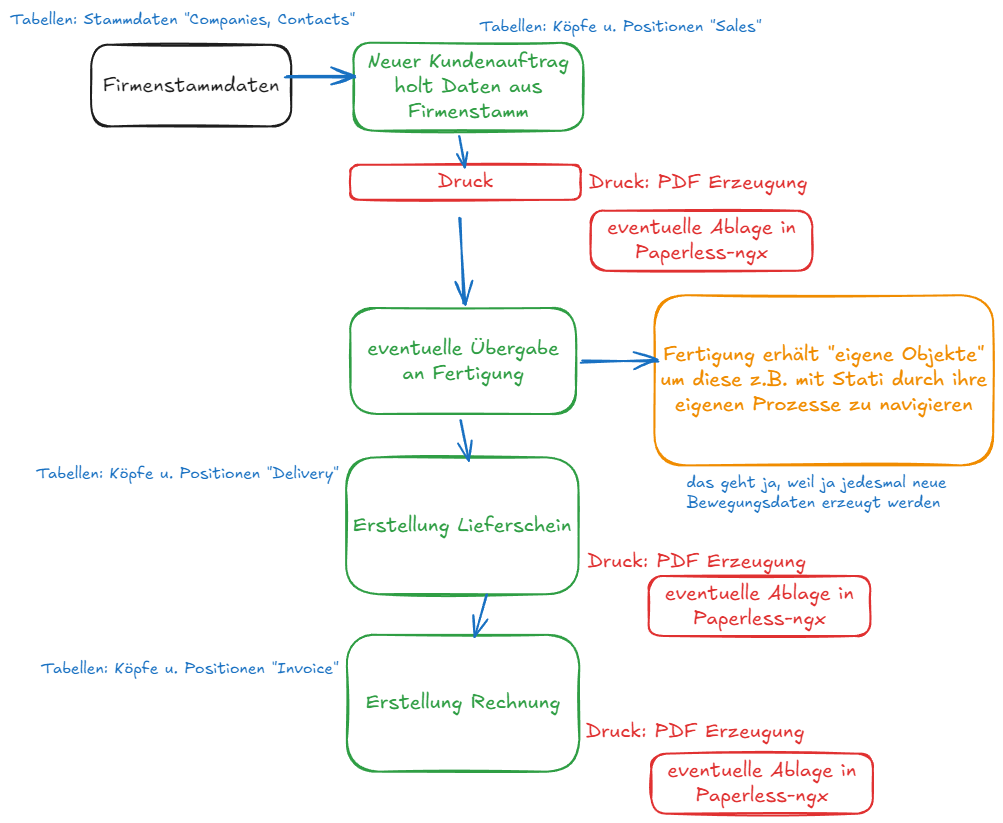
Die Hinweise auf „Paperless-ngx“ sollen andeuten, dass wir auch jedes erzeugte PDF in einem DMS automatisiert ablegen lassen könnten. Ich erwähne das hier, das müssen wir dann aber auch im Rahmen des „Deployments“ besprechen und die richtige Entscheidung fällen.
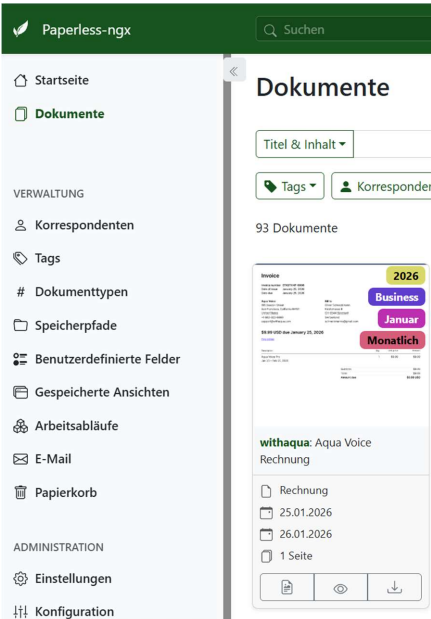
Papeless-ngx ist OpenSource und kann auch simpel implementiert werden. Ich könnte im Micro-ERP bei der Erzeugung diverser Dokumente immer gleich eine Version digital ablegen.
Grundsätzlich halte ich es für realistisch, euch ab Mitte Februar einen MVP (Minimum Viable Product) zeigen zu können. Diesen werden wir dann in „Tabu Lares“ bzw. in kleinen Workshops auf Bedienbarkeit und Logik prüfen. Ich programmiere zwar mit einem hohen Anteil an KI (unter Nutzung der Anthropic-Modelle Sonnet und Opus sowie Claude Code), dennoch erfordert die Planung viel Zeit, um die KI präzise zu steuern. Ich lasse die Funktionen bewusst „Feature by Feature“ entwickeln, prüfe den erzeugten Quellcode kontinuierlich und nutze spezielle Bibliotheken, um Flüchtigkeits- oder Typisierungsfehler auszuschließen. Fakt bleibt: Ohne KI-Unterstützung würde die Programmierung mehrere Monate dauern. Mit sind die Feature-Schritte recht beeindruckend schnell. Die weiter unten aufgeführte und angedeutete Funktionalität ist recht schnell entstanden.
Unten findet ihr einige „Sneak-Peek“-Bilder. Es wird eine Web-Applikation sein, aufgeteilt in Frontend (das Bediener-GUI), Backend (die Logik) und die zugrunde liegende Datenbank. Diese Komponenten können über die Cloud gehostet werden. Für den Anfang sollten wir jedoch darüber nachdenken, das System im internen Netzwerk (NAS) in einem Docker-Container laufen zu lassen – ganz nach dem Prinzip: Je weniger Stolpersteine, desto besser.